![]()
[Apr 21, 2024] New Professional-Machine-Learning-Engineer Exam Dumps with High Passing Rate
Get Professional-Machine-Learning-Engineer Braindumps & Professional-Machine-Learning-Engineer Real Exam Questions
Professional Machine Learning Engineer - Google Certified salary
The estimated average salary of Professional Machine Learning Engineer - Google is listed below:
- England: 87,200 POUND
- India: 8,580,000 INR
- United States: 114,000 USD
- Europe: 97,000 EURO
What is the duration, language, and format of Professional Machine Learning Engineer - Google
- Type of Questions: Multiple choice (MCQs), multiple answers
- Duration of Exam: 120 minutes
- No negative marking for wrong answers
- Language of Exam: English, Japanese, Korean
NEW QUESTION # 160
You work for a delivery company. You need to design a system that stores and manages features such as parcels delivered and truck locations over time. The system must retrieve the features with low latency and feed those features into a model for online prediction. The data science team will retrieve historical data at a specific point in time for model training. You want to store the features with minimal effort. What should you do?
- A. Store features in Bigtable as key/value data.
- B. Store features in Vertex Al Feature Store.
- C. Store features as a Vertex Al dataset and use those features to tram the models hosted in Vertex Al endpoints.
- D. Store features in BigQuery timestamp partitioned tables, and use the BigQuery Storage Read API to serve the features.
Answer: B
NEW QUESTION # 161
You work for a hospital that wants to optimize how it schedules operations. You need to create a model that uses the relationship between the number of surgeries scheduled and beds used You want to predict how many beds will be needed for patients each day in advance based on the scheduled surgeries You have one year of data for the hospital organized in 365 rows The data includes the following variables for each day
* Number of scheduled surgeries
* Number of beds occupied
* Date
You want to maximize the speed of model development and testing What should you do?
- A. Create a Vertex Al tabular dataset Tram an AutoML regression model, with number of beds as the target variable and number of scheduled minor surgeries and date features (such as day of the week) as the predictors
- B. Create a BigQuery table Use BigQuery ML to build a regression model, with number of beds as the target variable and number of scheduled surgeries and date features (such as day of week) as the predictors
- C. Create a Vertex Al tabular dataset Train a Vertex Al AutoML Forecasting model with number of beds as the target variable, number of scheduled surgeries as a covariate, and date as the time variable.
- D. Create a BigQuery table Use BigQuery ML to build an ARIMA model, with number of beds as the target variable and date as the time variable.
Answer: C
Explanation:
According to the official exam guide1, one of the skills assessed in the exam is to "design, build, and productionalize ML models to solve business challenges using Google Cloud technologies". Vertex AI AutoML Forecasting2 is a service that allows you to train and deploy custom time-series forecasting models for batch prediction. Vertex AI AutoML Forecasting simplifies the model development process by providing a graphical user interface and a no-code approach. You can use Vertex AI AutoMLForecasting to train a model by using your tabular data, and specify the target variable, the covariates, and the time variable. Vertex AI AutoML Forecasting automatically handles the feature engineering, model selection, and hyperparameter tuning. Therefore, option D is the best way to maximize the speed of model development and testing for the given use case. The other options are not relevant or optimal for this scenario. References:
* Professional ML Engineer Exam Guide
* Vertex AI AutoML Forecasting
* Google Professional Machine Learning Certification Exam 2023
* Latest Google Professional Machine Learning Engineer Actual Free Exam Questions
NEW QUESTION # 162
A company is observing low accuracy while training on the default built-in image classification algorithm in Amazon SageMaker. The Data Science team wants to use an Inception neural network architecture instead of a ResNet architecture.
Which of the following will accomplish this? (Choose two.)
- A. Customize the built-in image classification algorithm to use Inception and use this for model training.
- B. Create a support case with the SageMaker team to change the default image classification algorithm to Inception.
- C. Use custom code in Amazon SageMaker with TensorFlow Estimator to load the model with an Inception network, and use this for model training.
- D. Bundle a Docker container with TensorFlow Estimator loaded with an Inception network and use this for model training.
- E. Download and apt-get installthe inception network code into an Amazon EC2 instance and use this instance as a Jupyter notebook in Amazon SageMaker.
Answer: A,C
NEW QUESTION # 163
You are building a predictive maintenance model to preemptively detect part defects in bridges. You plan to use high definition images of the bridges as model inputs. You need to explain the output of the model to the relevant stakeholders so they can take appropriate action. How should you build the model?
- A. Use TensorFlow to create a deep learning-based model and use the sampled Shapley method to explain the model output.
- B. Use scikit-lean to build a tree-based model, and use partial dependence plots (PDP) to explain the model output.
- C. Use TensorFlow to create a deep learning-based model and use Integrated Gradients to explain the model output.
- D. Use scikit-learn to build a tree-based model, and use SHAP values to explain the model output.
Answer: C
Explanation:
According to the official exam guide1, one of the skills assessed in the exam is to "explain the predictions of a trained model". TensorFlow2 is an open source framework for developing and deploying machine learning and deep learning models. TensorFlow supports various model explainability methods, such as Integrated Gradients3, which is a technique that assigns an importance score to each input feature by approximating the integral of the gradients along the path from a baseline input to the actual input. Integrated Gradients can help explain the output of a deep learning-based model by highlighting the most influential features in the input images. Therefore, option C is the best way to build the model for the given use case. The other options are not relevant or optimal for this scenario. References:
* Professional ML Engineer Exam Guide
* TensorFlow
* Integrated Gradients
* Google Professional Machine Learning Certification Exam 2023
* Latest Google Professional Machine Learning Engineer Actual Free Exam Questions
NEW QUESTION # 164
You are training models in Vertex Al by using data that spans across multiple Google Cloud Projects You need to find track, and compare the performance of the different versions of your models Which Google Cloud services should you include in your ML workflow?
- A. Dataplex. Vertex Al Feature Store and Vertex Al TensorBoard
- B. Vertex Al Pipelines, Vertex Al Feature Store, and Vertex Al Experiments
- C. Dataplex. Vertex Al Experiments, and Vertex Al ML Metadata
- D. Vertex Al Pipelines: Vertex Al Experiments and Vertex Al Metadata
Answer: D
NEW QUESTION # 165
You work for a startup that has multiple data science workloads. Your compute infrastructure is currently on-premises. and the data science workloads are native to PySpark Your team plans to migrate their data science workloads to Google Cloud You need to build a proof of concept to migrate one data science job to Google Cloud You want to propose a migration process that requires minimal cost and effort. What should you do first?
- A. Create a Standard (1 master. 3 workers) Dataproc cluster, and run a Vertex Al Workbench notebook instance on it.
- B. Create a n2-standard-4 VM instance and install Java, Scala and Apache Spark dependencies on it.
- C. Create a Google Kubemetes Engine cluster with a basic node pool configuration install Java Scala, and Apache Spark dependencies on it.
- D. Create a Vertex Al Workbench notebook with instance type n2-standard-4.
Answer: A
Explanation:
According to the official exam guide1, one of the skills assessed in the exam is to "design, build, and productionalize ML models to solve business challenges using Google Cloud technologies". Dataproc2 is a fully managed, fast, and easy-to-use service for running Apache Spark and Apache Hadoop clusters on Google Cloud. Dataproc supports PySpark workloads and provides a simple way to migrate your existing Spark jobs to the cloud. You can create a Dataproc cluster with a few clicks or commands, and run your PySpark jobs on it. You can also use Vertex AI Workbench3, a managed notebook service, to create and run PySpark notebooks on Dataproc clusters. This way, you can interactively develop and test your PySpark code on the cloud. Therefore, option C is the best way to build a proof of concept to migrate one data science job to Google Cloud with minimal cost and effort. The other options are not relevant or optimal for this scenario.
References:
* Professional ML Engineer Exam Guide
* Dataproc
* Vertex AI Workbench
* Google Professional Machine Learning Certification Exam 2023
* Latest Google Professional Machine Learning Engineer Actual Free Exam Questions
NEW QUESTION # 166
You work on a growing team of more than 50 data scientists who all use AI Platform. You are designing a strategy to organize your jobs, models, and versions in a clean and scalable way. Which strategy should you choose?
- A. Set up a BigQuery sink for Cloud Logging logs that is appropriately filtered to capture information about AI Platform resource usage. In BigQuery, create a SQL view that maps users to the resources they are using
- B. Separate each data scientist's work into a different project to ensure that the jobs, models, and versions created by each data scientist are accessible only to that user.
- C. Set up restrictive IAM permissions on the AI Platform notebooks so that only a single user or group can access a given instance.
- D. Use labels to organize resources into descriptive categories. Apply a label to each created resource so that users can filter the results by label when viewing or monitoring the resources.
Answer: C
NEW QUESTION # 167
You are developing an image recognition model using PyTorch based on ResNet50 architecture. Your code is working fine on your local laptop on a small subsample. Your full dataset has 200k labeled images You want to quickly scale your training workload while minimizing cost. You plan to use 4 V100 GPUs. What should you do? (Choose Correct Answer and Give Reference and Explanation)
- A. Create a Google Kubernetes Engine cluster with a node pool that has 4 V100 GPUs Prepare and submit a TFJob operator to this node pool.
- B. Configure a Compute Engine VM with all the dependencies that launches the training Train your model with Vertex Al using a custom tier that contains the required GPUs.
- C. Create a Vertex Al Workbench user-managed notebooks instance with 4 V100 GPUs, and use it to train your model
- D. Package your code with Setuptools. and use a pre-built container Train your model with Vertex Al using a custom tier that contains the required GPUs.
Answer: A
Explanation:
Google Kubernetes Engine (GKE) is a powerful and easy-to-use platform for deploying and managing containerized applications. It allows you to create a cluster of virtual machines that are pre-configured with the necessary dependencies and resources to run your machine learning workloads. By creating a GKE cluster with a node pool that has 4 V100 GPUs, you can take advantage of the powerful processing capabilities of these GPUs to train your model quickly and efficiently.
You can then use the Kubernetes Framework such as TFJob operator to submit the job of training your model, which will automatically distribute the workload across the available GPUs.
Reference:
Google Kubernetes Engine
TFJob operator
Vertex Al
NEW QUESTION # 168
You are training an object detection model using a Cloud TPU v2. Training time is taking longer than expected. Based on this simplified trace obtained with a Cloud TPU profile, what action should you take to decrease training time in a cost-efficient way?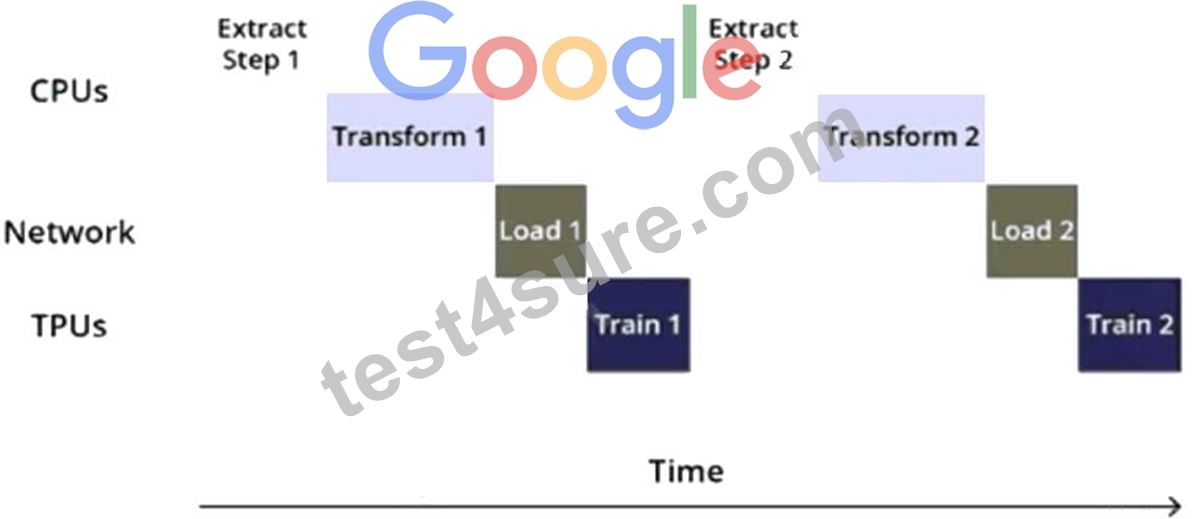
- A. Rewrite your input function using parallel reads, parallel processing, and prefetch.
- B. Move from Cloud TPU v2 to Cloud TPU v3 and increase batch size.
- C. Rewrite your input function to resize and reshape the input images.
- D. Move from Cloud TPU v2 to 8 NVIDIA V100 GPUs and increase batch size.
Answer: B
NEW QUESTION # 169
You recently developed a deep learning model using Keras, and now you are experimenting with different training strategies. First, you trained the model using a single GPU, but the training process was too slow.
Next, you distributed the training across 4 GPUs using tf.distribute.MirroredStrategy (with no other changes), but you did not observe a decrease in training time. What should you do?
- A. Use a TPU with tf.distribute.TPUStrategy.
- B. Create a custom training loop.
- C. Distribute the dataset with tf.distribute.Strategy.experimental_distribute_dataset
- D. Increase the batch size.
Answer: D
Explanation:
* Option A is incorrect because distributing the dataset with
tf.distribute.Strategy.experimental_distribute_dataset is not the most effective way to decrease the
* training time. This method allows you to distribute your dataset across multiple devices or machines, by creating a tf.data.Dataset instance that can be iterated over in parallel1. However, this option may not improve the training time significantly, as it does not change the amount of data or computation that each device or machine has to process. Moreover, this option may introduce additional overhead or complexity, as it requires you to handle the data sharding, replication, and synchronization across the devices or machines1.
* Option B is incorrect because creating a custom training loop is not the easiest way to decrease the training time. A custom training loop is a way to implement your own logic fortraining your model, by using low-level TensorFlow APIs, such as tf.GradientTape, tf.Variable, or tf.function2. A custom training loop may give you more flexibility and control over the training process, but it also requires more effort and expertise, as you have to write and debug the code for each step of the training loop, such as computing the gradients, applying the optimizer, or updating the metrics2. Moreover, a custom training loop may not improve the training time significantly, as it does not change the amount of data or computation that each device or machine has to process.
* Option C is incorrect because using a TPU with tf.distribute.TPUStrategy is not a valid way to decrease the training time. A TPU (Tensor Processing Unit) is a custom hardware acceleratordesigned for high-performance ML workloads3. A tf.distribute.TPUStrategy is a distribution strategy that allows you to distribute your training across multiple TPUs, by creating a tf.distribute.TPUStrategy instance that can be used with high-level TensorFlow APIs, such as Keras4. However, this option is not feasible, as Vertex AI Training does not support TPUs as accelerators for custom training jobs5. Moreover, this option may require significant code changes, as TPUs have different requirements and limitations than GPUs.
* Option D is correct because increasing the batch size is the best way to decrease the training time. The batch size is a hyperparameter that determines how many samples of data are processed in each iteration of the training loop. Increasing the batch size may reduce the training time, as it reduces the number of iterations needed to train the model, and it allows each device or machine to process more data in parallel. Increasing the batch size is also easy to implement, as it only requires changing a single hyperparameter. However, increasing the batch size may also affect the convergence and the accuracy of the model, so it is important to find the optimal batch size that balances the trade-off between the training time and the model performance.
References:
* tf.distribute.Strategy.experimental_distribute_dataset
* Custom training loop
* TPU overview
* tf.distribute.TPUStrategy
* Vertex AI Training accelerators
* [TPU programming model]
* [Batch size and learning rate]
* [Keras overview]
* [tf.distribute.MirroredStrategy]
* [Vertex AI Training overview]
* [TensorFlow overview]
NEW QUESTION # 170
You want to train an AutoML model to predict house prices by using a small public dataset stored in BigQuery. You need to prepare the data and want to use the simplest most efficient approach. What should you do?
- A. Use Dataflow to preprocess the data Write the output in TFRecord format to a Cloud Storage bucket.
- B. Write a query that preprocesses the data by using BigQuery Export the query results as CSV files and use those files to create a Vertex Al managed dataset.
- C. Write a query that preprocesses the data by using BigQuery and creates a new table Create a Vertex Al managed dataset with the new table as the data source.
- D. Use a Vertex Al Workbench notebook instance to preprocess the data by using the pandas library Export the data as CSV files, and use those files to create a Vertex Al managed dataset.
Answer: C
NEW QUESTION # 171
You are working on a Neural Network-based project. The dataset provided to you has columns with different ranges. While preparing the data for model training, you discover that gradient optimization is having difficulty moving weights to a good solution. What should you do?
- A. Improve the data cleaning step by removing features with missing values.
- B. Use the representation transformation (normalization) technique.
- C. Change the partitioning step to reduce the dimension of the test set and have a larger training set.
- D. Use feature construction to combine the strongest features.
Answer: B
Explanation:
https://developers.google.com/machine-learning/data-prep/transform/transform-numeric
- NN models needs features with close ranges
- SGD converges well using features in [0, 1] scale
- The question specifically mention "different ranges"
Documentation - https://developers.google.com/machine-learning/data-prep/transform/transform-numeric
NEW QUESTION # 172
You built a deep learning-based image classification model by using on-premises dat a. You want to use Vertex Al to deploy the model to production Due to security concerns you cannot move your data to the cloud. You are aware that the input data distribution might change over time You need to detect model performance changes in production. What should you do?
- A. Use Vertex Explainable Al for model explainability Configure example-based explanations.
- B. Create a Vertex Al Model Monitoring job. Enable feature attribution skew and dnft detection for your model.
- C. Use Vertex Explainable Al for model explainability Configure feature-based explanations.
- D. Create a Vertex Al Model Monitoring job. Enable training-serving skew detection for your model.
Answer: B
NEW QUESTION # 173
You need to use TensorFlow to train an image classification model. Your dataset is located in a Cloud Storage directory and contains millions of labeled images Before training the model, you need to prepare the dat a. You want the data preprocessing and model training workflow to be as efficient scalable, and low maintenance as possible. What should you do?
- A. 1 Create a Jupyter notebook that uses an n1-standard-64, V100 GPU Vertex Al Workbench instance.
2 Write a Python scnpt that copies the images into multiple Cloud Storage directories, where each directory is named according to the corresponding label.
3 Reference tf ds. f older_dataset. imageFolder in the training script.
4. Train the model by using the Workbench instance. - B. 1 Create a Dataflow job that moves the images into multiple Cloud Storage directories, where each directory is named according to the corresponding label.
2 Reference tfds.fclder_da-asst.imageFclder in the training script.
3. Train the model by using Vertex AI Training with a V100 GPU. - C. 1 Create a Dataflow job that creates sharded TFRecord files in a Cloud Storage directory.
2 Reference tf .data.TFRecordDataset in the training script.
3. Train the model by using Vertex Al Training with a V100 GPU. - D. 1 Create a Jupyter notebook that uses an n1-standard-64, V100 GPU Vertex Al Workbench instance.
2 Write a Python script that creates sharded TFRecord files in a directory inside the instance
3. Reference tf. da-a.TFRecrrdDataset in the training script.
4. Train the model by using the Workbench instance.
Answer: C
NEW QUESTION # 174
You work for an auto insurance company. You are preparing a proof-of-concept ML application that uses images of damaged vehicles to infer damaged parts Your team has assembled a set of annotated images from damage claim documents in the company's database The annotations associated with each image consist of a bounding box for each identified damaged part and the part name. You have been given a sufficient budget to tram models on Google Cloud You need to quickly create an initial model What should you do?
- A. Download a pre-trained object detection mode! from TensorFlow Hub Fine-tune the model in Vertex Al Workbench by using the annotated image data.
- B. Train an object detection model in AutoML by using the annotated image data.
- C. Train an object detection model in Vertex Al custom training by using the annotated image data.
- D. Create a pipeline in Vertex Al Pipelines and configure the AutoMLTrainingJobRunOp compon it to train a custom object detection model by using the annotated image data.
Answer: B
NEW QUESTION # 175
......
Professional-Machine-Learning-Engineer Dumps To Pass Google Exam in 24 Hours - Test4Sure: https://www.test4sure.com/Professional-Machine-Learning-Engineer-pass4sure-vce.html
Google Professional-Machine-Learning-Engineer Actual Questions and Braindumps: https://drive.google.com/open?id=1HmGT3GKb8ZqBYKlnlGCHdBVIyLH4US0e